경량 패턴
공유(Sharing)을 통해 많은 수의 소립(fine-grained) 객체들을 효과적으로 지원합니다.
여러 게임에서 볼 수 있는 숲이나 여러 배경과 같은 장면들을 제작할때에 '경량' 패턴으로 종종 구현 하기도 합니다.
숲에 들어갈 나무들
숲을 글로는 몇 문장으로 표현할 수 있지만, 실시간 게임으로 구현하는 것은 전혀 다른 이야기 입니다. 나무들이 화면을 가득 채운 숲을 볼 때, 그래픽스 프로그래머는 1초에 60번씩 GPU에 전달해야 하는 몇백만 개의 폴리곤을 보고 있습니다.
수천 그루가 넘는 나무마다 각각 수천 폴리곤의 형태로 표현해야 하고, 설사 메모리가 충분하다고 해도, 이런 숲을 그리기 위해서는 전체 데이터를 CPU에서 GPU로 전달해야 합니다. 나무마다 필요한 데이터는 다음과 같습니다.
- 줄기, 가지, 잎의 형태를 나타내는 폴리곤 메시
- 나무 껍질과 잎사귀 텍스처
- 숲에서의 위치와 방향
- 각각의 나무가 다르게 보이도록 크기와 음영 같은 값을 조절할 수 있는 매개변수
코드로 표현하자면 다음과 같이 표현할 수 있습니다.
class Tree
{
private:
Mesh mesh;
Texture bark;
Texture leaves;
Vector position;
double height;
double thickness;
Color barkTint;
Color leafTint;
}
데이터가 많은 데다가 메시와 텍스처는 크기도 크고 이렇게 많은 객체로 이루어진 숲 전체는 1프레임에 GPU로 모두 전달하기에는 양이 너무 많습니다. 다행히 검증된 해결책이 있는데 핵심으로는 숲에 나무가 수천 그루 넘게 있다고 해도 대부분 비슷해 보인다는 점을 이용합니다. 즉, 나무 객체에 들어 있는 데이터 대부분이 인스턴스별로 많이 다르지 않다고 볼 수 있습니다.
일단 객체를 반으로 쪼개어 이런 점을 명시적으로 모델링을 할 수 있으니 모든 나무가 다 같이 사용하는 데이터를 뽑아내 새로운 클래스를 작성해보겠습니다.
class TreeModel
{
private:
Mesh mesh; // 공통으로 사용될 메시
Texture bark; // 나무 껍질 텍스처
Texture leaves; // 나뭇잎 텍스처
}게임 내에서 같은 메시와 텍스처를 여러 번 메모리에 올릴 이유가 전혀 없기 때문에 `TreeModel`객체는 하나만 존재하게 됩니다. 이제 각 나무 인스턴스는 공유 객체인 `TreeModel`을 참조하기만 하며 `Tree`클래스에는 인스턴스 별로 다른 상태 값만 남겨두겠습니다.
class Tree
{
private:
TreeModel* model; // 공통된 나무 모델
Vector position; // 나무들의 위치
double height; // 나무들의 높이
double thickness; // 나무들의 두께
Color barkTint; // 나무껎질의 색상
Color leafTint; // 나뭇잎의 색상
}그림으로 그려보면 다음과 같이 볼 수 있습니다.
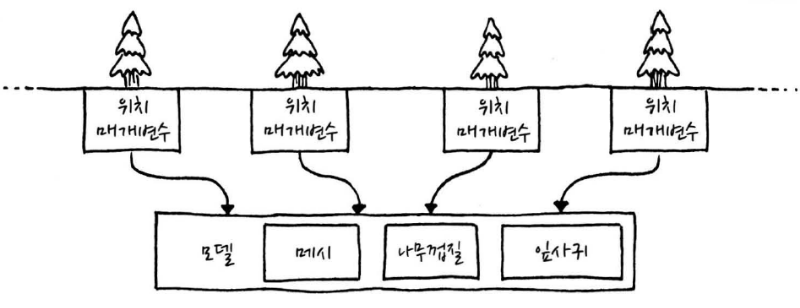
주메모리에 객체를 저장하기 위해서라면 충분하지만 렌더링은 또 다른 이야기입니다. 화면에 숲을 그리기 위해서는 먼저 데이터를 GPU로 전달해야 하고, 또한 어떤 식으로 자원을 공유하고 있는지를 그래픽 카드도 이해할 수 있는 방식으로 표현해야 합니다.
수천 개의 인스턴스
GPU는 객체 공유 개념을 이해하는 것이 아니라, 단일 버퍼에서 공유 데이터를 불러와 여러 인스턴스를 효율적으로 렌더링할 수 있도록 최적화된 방식을 지원합니다. 최신 그래픽 API(예: Direct3D, OpenGL)에서는 인스턴스 렌더링을 통해 반복되는 데이터를 줄이고, 개별적으로 변하는 속성만 별도로 전송하여 CPU-GPU 간 데이터 전송을 최소화할 수 있습니다.
다행히, 요즘 나오는 그래픽 카드나 API에서는 이런 기능을 제공해줍니다 예를 들어 Direct3D, OpenGl 모두 인스턴스 렌더링(instanced rendering)을 지원하고 있습니다.
이들 API에서 인스턴스 렌더링을 하려면 데이터 스트림이 두 개 필요하며 첫 번째 스트림에는 숲 렌더링 예제의 메시나 텍스처처럼 여러 번 렌더링되어야 하는 공유 데이터가 들어갑니다. 두 번째 스트림에는 인스턴스 목록과, 이들 인스턴스를 첫 번째 스트림 데이터를 이용해 그릴 때 각기 다르게 보이기 위해 필요한 매개변수들이 들어갑니다, 이제 그리기 호출 한 번만으로 전체 숲을 다 그릴 수가 있게 되었습니다. 조금 더 풀어서 설명드리겠습니다.
1. 데이터 스트림이 두 개 필요하다.
- 첫 번째 스트림: 여러 번 반복해서 사용할 수 있는 공유데이터를 담고 있습니다. 예를 들어 숲을 렌더링 할때 나무의
모양(메시, Mesh) 나 질감(텍스처, Texture) 를 가지고 있습니다. - 두 번째 스트림: 그 나무들이 어디에 배치될지(위치, 크기, 회전값 등) 그리고 개별 나무마다 다른 특성을 적용할 정보를 담고 있습니다.
2. 그리기 호출(Draw) 한 번만으로 모든 나무를 그릴 수 있다.
- 숲에 1000그루의 나무가 있다면, 기존 방식이라면 1000번의 그리기 호출을 해야 했지만 인스턴스 렌더링을 사용하면 한 번의 드로우 호출만으로 1000그루의 나무를 그릴 수 있습니다.
- 그 이유는 첫 번째 스트림에서 나무의 기본 형태를 가져오고, 두 번째 스트림에서 나무의 배치와 개별 속성을 정하기 때문입니다.
💡 쉽게 비유하자면?
- 종이접기 공장에 같은 모양의 종이학을 100개 접어야 한다고 가정했을때
- 첫 번째 스트림: 종이학 접는 방법 (공유 데이터, 즉 메시 & 텍스처)
- 두 번째 스트림: 종이학을 어디에 놓을지, 색깔을 어떻게 할지 등의 정보(인스턴스별 매개변수)
- 종이학을 하나하나 접는 게 아니라, 같은 방법을 이용해 한 번에 100개를 생산한다.
즉, 반복되는 데이터를 공유하고, 개별 차이점만 추가해서 최적화된 방식으로 렌더링하는 기법을 인스턴스 렌더링이라고 합니다.
경량 패턴
경량 패턴이라는 이름에서 알 수 있듯이 경량 패턴은 어떤 객체의 개수가 너무 많아서 좀 더 가볍게 만들고 싶을 때 사용합니다. 인스턴스 렌더링에서는 메모리 크기보다는 렌더링할 나무 데이터를 하나씩 GPU로 보내는 데 걸리는 시간이 중요하지만, 기본 개념은 경량 패턴과 같습니다.
이런 문제를 해결하기 위해 경량 패턴은 객체 데이터를 두 종류로 나누게 됩니다. 먼저 모든 객체의 데이터 값이 같아서 공유할 수 있는 데이터를 모으며 GoF는 고유 상태(intrinsic state) 라고 부릅니다. 예제에서는 나무 형태나 텍스처가 이에 해당됩니다.
나머지 데이터는 인스턴스별로 값이 다른 외부 상태(extrinsic state)에 해당 합니다. 예제에서는 나무의 위치, 크기, 색 등이 이에 해당됩니다. 경량 패턴은 한 개의 고유 상태를 다른 객체에서 공유하게 만들어 메모리 사용량을 줄이고 있습니다.
여기까지만 보신다면 기초적인 자원 공유 기법이지 패턴이라고 부를 정도는 아닌 것 처럼 보이지만 이 예제에서는 공유 상태를 `TreeModel` 클래스로 깔끔하게 분리할 수 있어서 그렇게 보일 수도 있습니다.
공유 객체가 명확하지 않는 경우 경량 패턴은 잘 드러나 보이지 않으며 그런 경우에는 하나의 객체가 신기하게도 여러 곳에 동시에 존재하는 것처럼 보입니다.
지형 정보
나무를 심을 땅도 게임에서 표현해야 합니다. 보통 풀, 흙, 언덕, 호수, 강 같은 다양한 지형을 이어 붙여서 땅을 만들며 여기에서는 땅을 타일 기반으로 만들 것입니다. 즉, 땅은 작은 타일들이 모여 있는 거대한 격자형태이며 모든 타일은 지형 종류 중 하나로 덮여 있습니다. 지형 종류에는 게임 플레이에 영향을 주는 여러 속성이 들어 있습니다.
- 플레이어가 얼마나 빠르게 이동할 수 있는지를 결정하는 이동 비용 값
- 강이나 바다처럼 보트로 건너갈 수 있는 곳인지 여부
- 렌더링할 때 사용할 텍스처
이러한 속성들이 있으며 최적화를 위해서는 이들 속성을 지형 타일마다 따로 저장하지 않고 대신에 지형 종류에 열거형을 사용하는게 일반적입니다.
enum Terrain
{
TERRAIN_GRASS,
TERRAIN_HILL,
TERRAIN_RIVER
// 그 외 다른 지형들
}이제 월드는 지형을 거대한 격자로 관리하게 됩니다.
class World
{
private:
Terrain tiles[WIDTH][HEIGHT]; //2차원 배열에 저장
};타일 관련 데이터는 다음과 같이 얻을 수가 있습니다.
int World::getMovementCost(int x, int y)
{
switch (tiles[x][y])
{
case TERRAIN_GRASS: return 1;
case TERRAIN_HILL: return 3;
case TERRAIN_RIVER: return 2;
// 그 외 다른 지형들
}
}
bool World::isWater(int x, int y)
{
switch (tiles[x][y])
{
case TERRAIN_GRASS: return false;
case TERRAIN_HILL: return false;
case TERRAIN_RIVER: return true;
// 그 외 다른 지형들
}
}해당 코드도 동작을 하지만 지저분 하고 이동 비용이나 물인지 땅인지 여부는 지형에 관한 데이터인데 이 코드에서는 하드코딩되어 있습니다. 게다가 같은 지형 종류에 대한 데이터가 여러 메서드에 나뉘어 있습니다. 이런 데이터는 하나로 합쳐서 캡슐화 하여 아래와 같이 지형 클래스로 만드는것이 더 나은 방법이 됩니다.
class Terrain
{
public:
Terrain(int movementCost, bool isWater, Texture texture)
: movementCost_(movementCost),
isWater_(isWater),
texture_(texture){}
int getMovementCost() const { return movementCost_; }
bool isWater() const { return isWater_; }
const Texture& getTexture() const { return Texture_; }
private:
int movementCost_;
bool isWater_;
Texture texture_;
};하지만 타일마다 `Terrain` 인스턴스를 하나씩 만드는 비용은 피하고 싶습니다, `Terrain` 클래스에는 타일 위치와 관련된 내용은 전혀 없는 것을 볼 수 있습니다. 경량 패턴식으로 얘기하자면 모든 지형 상태는 '고유'하다 라고 볼 수 있습니다. 따라서 지형 종류 별로 `Terrain` 객체가 여러 개 있을 필요가 없습니다. 지형에 들어가는 모든 풀 밭 타일은 전부 동일하며 `World` 클래스 격자 멤버 변수에 열거형이나 `Terrain` 객체 대신 `Terrain` 객체의 포인터를 넣을 수 있습니다.
class World
{
private:
Terrain* tiles[WIDTH][HEIGHT];
// 그 외..
};지형 종류가 같은 타일들은 모두 같은 `Terrain` 인스턴스 포인터를 갖게 됩니다.
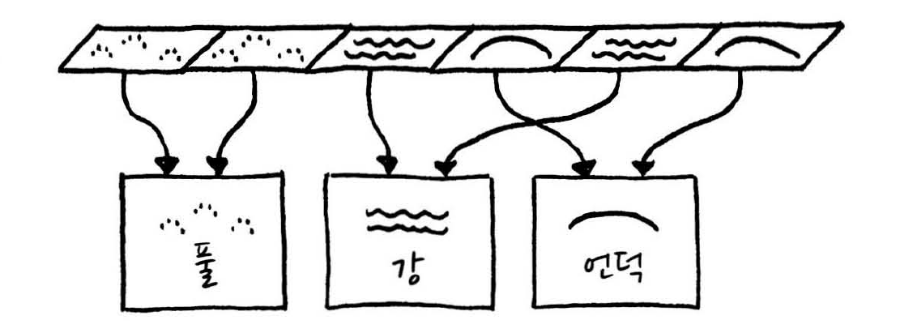
`Terrain` 인스턴스가 여러 곳에서 사용되다 보니, 동적으로 할당하면 생명주기를 관리하기가 좀 더 어려워 집니다. 따라서 `World` 클래스에 저장하겠습니다.
class World
{
public:
World()
: grassTerrain_(1, false, GRASS_TEXTURE)
hillTerrain_(3, false, HILL_TEXTURE),
riverTerrain_(2, true, RIVER_TEXTURE)
{}
private:
Terrain grassTerrain_;
Terrain hillTerrain_;
Terrain riverTerrain_;
// 그 외..
};이렇게 함으로써 다음과 같이 땅 위를 채울 수가 있습니다.
class World
{
public:
World()
: grassTerrain_(1, false, GRASS_TEXTURE)
hillTerrain_(3, false, HILL_TEXTURE),
riverTerrain_(2, true, RIVER_TEXTURE)
{}
private:
Terrain grassTerrain_;
Terrain hillTerrain_;
Terrain riverTerrain_;
// 그 외..
};
void World::generateTerrain()
{
// 땅에 풀을 채운다.
for (int x = 0; x < WIDTH; x++)
{
for (int y = 0;y < HEIGHT; y++)
{
//언덕을 몇 개 놓는다.
if (random(10) == 0)
{
tiles[x][y] = &hillTerrain_;
}
else
{
tiles[x][y] = &grassTerrain_;
}
}
}
// 강을 하나 놓는다.
int x = random(WIDTH);
for (int y = 0; y < HEIGHT; y++)
{
tiles[x][y] = &riverTerrain_;
}
}이제 지형 속성 값을 `World`의 메서드 대신 `Terrain` 객체에서 바로 얻을 수가 있습니다.
const Terrain& World::getTile(int x, int y) const
{
return *tiles[x][y]
}`World` 클래스는 더 이상 지형의 세부 정보와 커플링 되지 않으며 타일 속성은 `Terrain` 객체에서 바로 얻을 수가 있습니다.
int cost = world.getTile(2,3).getMovementCost()이제 객체로 작동하는 그럴싸한 API가 되었습니다.
성능에 대해서
⚡ 핵심 개념: 간접 조회(Indirect Lookup)
- 열거형(enum) 방식 → 배열 인덱싱처럼 직접 값을 가져옴 (빠름)
- 포인터 방식(객체 참조) → 한 단계 거쳐서 값을 가져옴 (느릴 수도 있음)
- 즉, 포인터를 따라가야 하므로 캐시 미스(cache miss)가 발생할 가능성이 있음
(CPU 캐시를 제대로 활용하지 못하면 성능이 떨어질 수도 있음)
🎯 결론: 직접 측정(프로파일링) 없이 성능을 단정하지 마라!
- 최적화는 직접 측정하는 게 중요하다.
(현대 컴퓨터는 복잡해서 단순한 예측만으로 최적화를 하면 안 됨) - 실제 측정해보니, 경량 패턴을 사용해도 성능이 나빠지지 않았고 오히려 더 빨랐다!
→ 하지만 메모리 배치 방식에 따라 달라질 수 있음 - 따라서, 객체를 많이 만들지 않으면서도 객체지향 방식의 장점을 살릴 수 있는 "경량 패턴"을 고려해볼 만하다.
'Software Engineering > Design Pattern' 카테고리의 다른 글
| 관찰자 패턴(Observer Pattern) (0) | 2025.03.02 |
|---|---|
| 명령 패턴 (0) | 2025.02.23 |